变局与挑战
AI模型参数持续攀升,受限于网络通信性能,大规模分布式GPU集群的计算效率,难以实现线性增长,智算中心的发展面临重重挑战
组网规模需求大
大模型训练和分布式并行计算,网络需要支持数千甚至十万算卡集群规模的建设
网络性能要求高
大模型的机间网络通信占比提升,带宽接入及带宽利用率,成为影响训练效率的网络关键指标
训练连续性要求高
组网规模大,训练负载高,可靠性不足会拉长训练周期,降低训练效率
上线慢、运维难
项目建设周期紧,在训练期间如果出现网络故障,会影响整个训练任务的进度
锐捷网络AI-Fabric智算中心网络解决方案
满足AI模型的训练需求
十万卡集群,超大规模组网
极高吞吐网络,极致算力释放
高可靠,训练任务一次“跑到底”
简部署、智运维
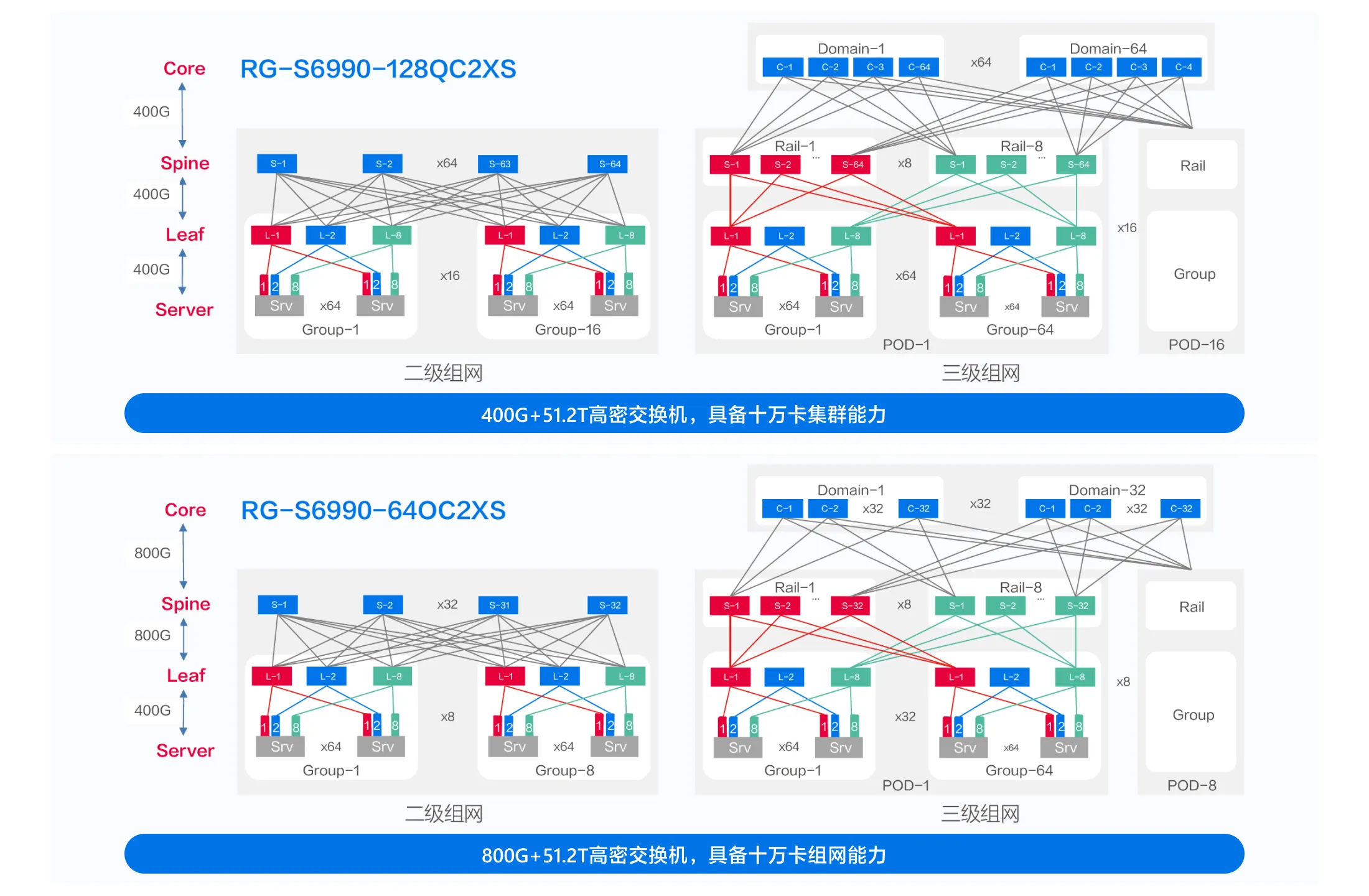
十万卡集群
超大规模组网
- 多轨组网架构,支持按需灵活部署
- 三级组网最大支持十万卡规模集群
咨询详情
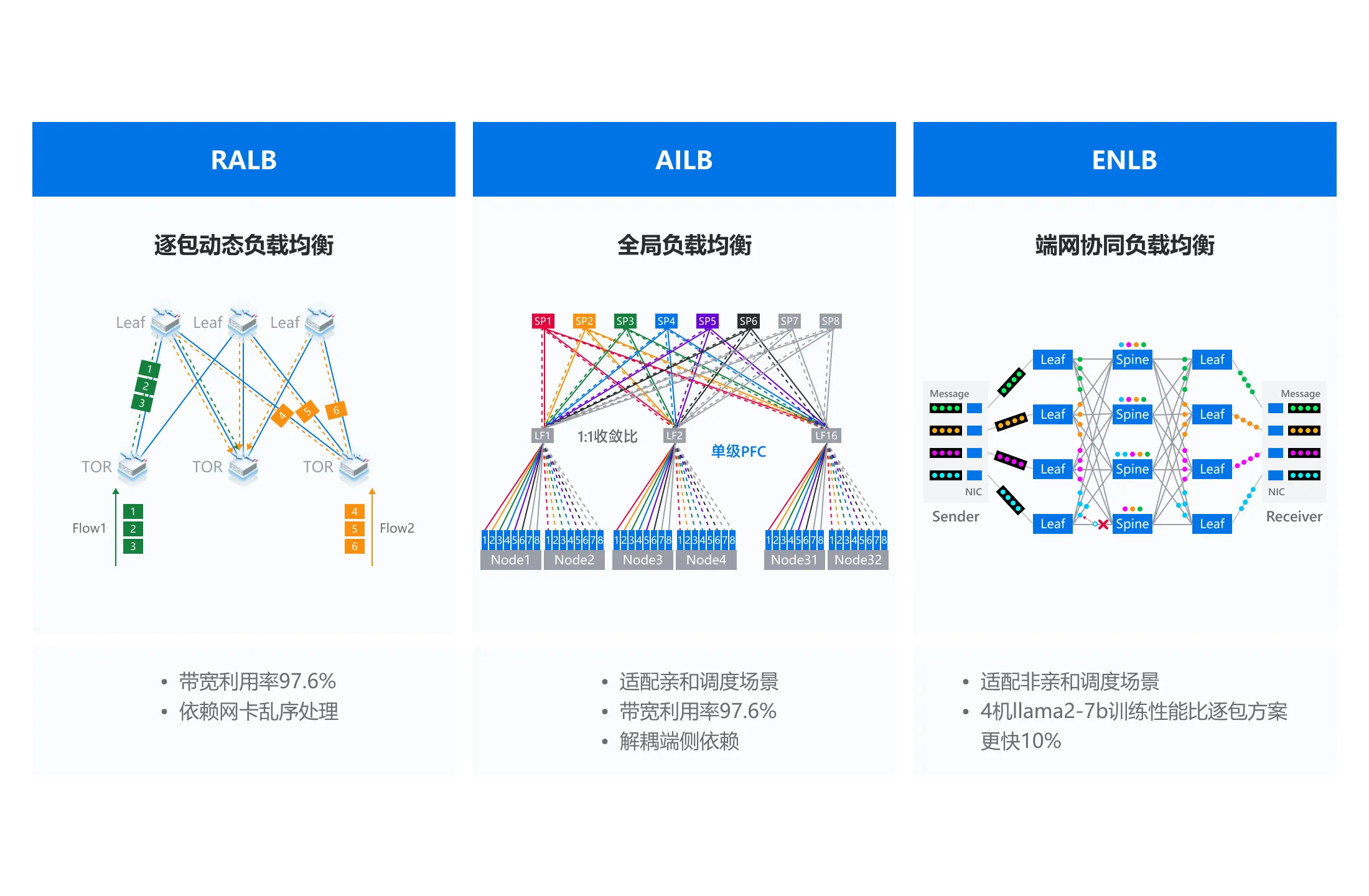
极高吞吐网络
极致算力释放
- 400G/800G RoCE无损网络设计,低时延、高带宽
- 基于不同场景的均衡方案(RALB/AILB/ENLB),带宽利用率达97%
咨询详情
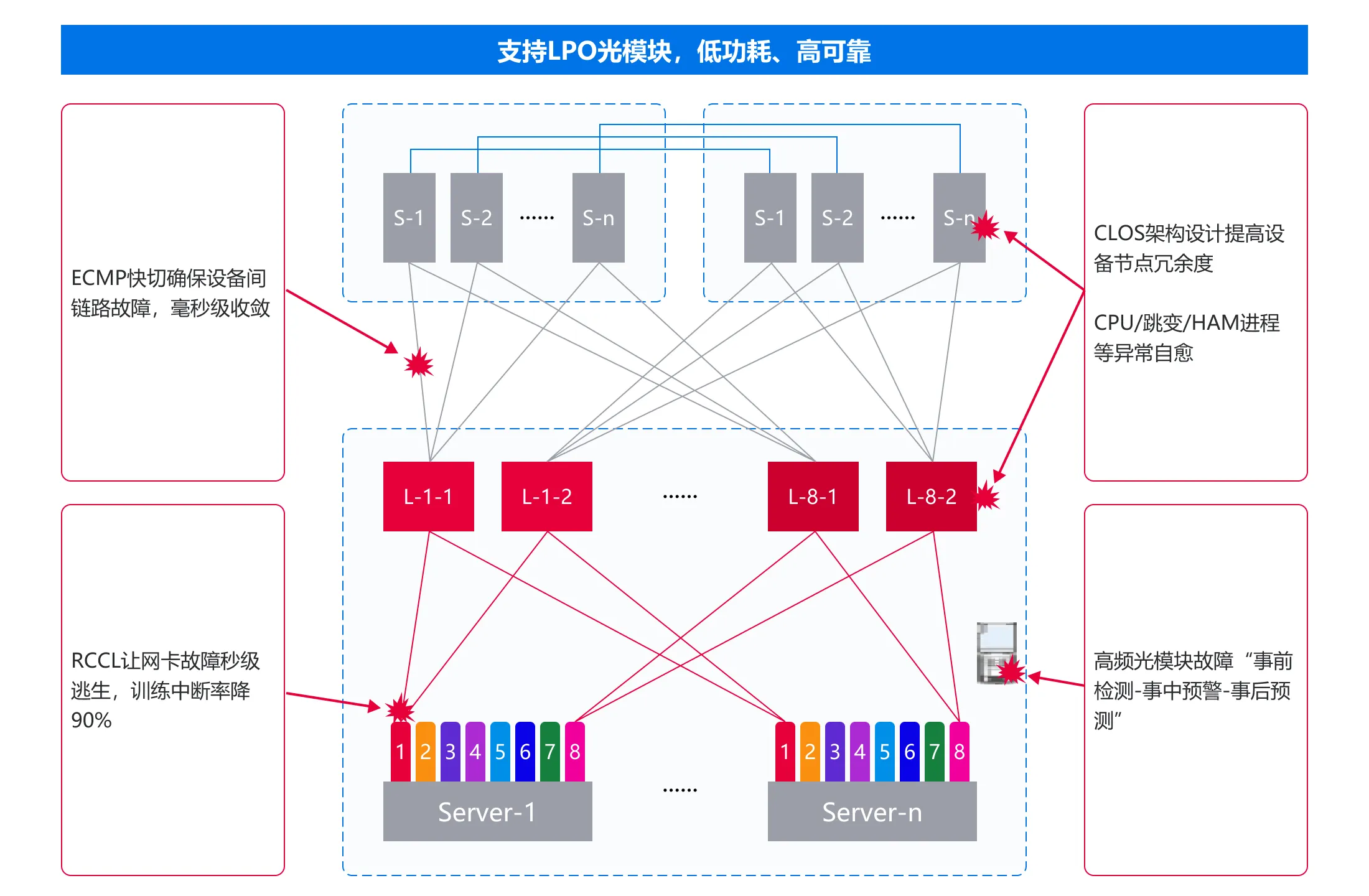
高可靠,训练任务一次“跑到底”
- 从网卡、光模块、链路到交换机,多维度的高可靠设计,实现算力集群的高稳定性
咨询详情
简部署、智运维
资源了然于胸
- 开局一键部署,千卡集群7天交付
- 云端算力仿真模拟,性能、收益智能分析
- “网络+光模块+服务器”可视化监测,故障快速定位、隔离、恢复
- 网侧+端侧自适应辅助调优,降低技术门槛
咨询详情
明星产品
 RG-S6980-64QC
RG-S6980-64QC
64口400GbE交换机
了解更多
 RG-S6980-128DC
RG-S6980-128DC
128口200GbE交换机
了解更多
 RG-S6990-128QC2XS
RG-S6990-128QC2XS
128口400GbE交换机
了解更多
 RG-S6990-64OC2XS
RG-S6990-64OC2XS
64口800GbE交换机
了解更多
相关资源
媒体报道

《IT168 | AIGC浪潮之下,锐捷如何为算力网络注入“智能”》
2024-07-10
彩页
《锐捷AI-Fabric智算中心网络解决方案》
查看详情
技术博文
《快问快答 | 你关心的AIGC方案相关问题,都在这里!》
查看详情
《技术盛宴|浅谈AIGC算力网络中LPO模块的技术优势》
查看详情
《技术盛宴 | 多维度对比分析AIGC网络网卡双上联技术架构》
查看详情