






大型数据中心BGP路由协议规划
【BGP路由协议】本文借鉴了国内外大型互联网公司的实践经验,总结了一些规划和运营BGP网络的方法。






本文借鉴了国内外大型互联网公司的实践经验,总结了一些规划和运营BGP网络的方法
前言
在之前的文章《大型数据中心路由协议选择》中,介绍到边界网关协议(BGP)已经成为大型数据中心(IDC)优先选择的路由协议。众所周知,BGP最初是为不同自治系统之间的互通设计的,而并非面向IDC内部。在BGP引入到数据中心场景时,也曾经出现“水土不服”,问题诸多。面对这些问题,聪明的网络工程师们对BGP做了哪些优化?数据中心BGP网络规划需要考虑哪些问题?本文借鉴了国内外大型互联网公司的实践经验,抛砖引玉,粗浅分析一二。
大型数据中心组网架构
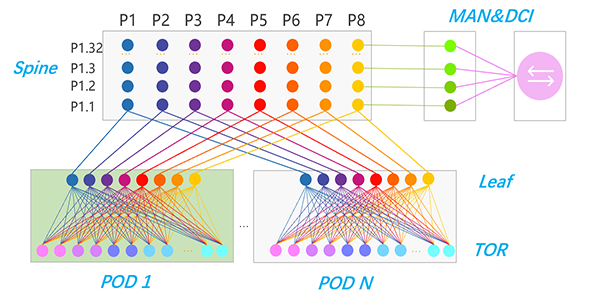
▲ 图1:大型数据中心Spine-Leaf组网架构(内网)
面对数据中心业务对可靠性近乎苛刻的要求,现代数据中心网络的重要设计方法是假定网络设备和链路都是不可靠的:目标在于当这些不可靠的设备或者链路出现故障时,也能通过自愈消除对业务产生的不良影响。基于此,Leaf-Spine (Leaf:叶节点,Spine:脊节点)的组网架构已经成为数据中心主流。如图1所示,这种CLOS多级交换网络为数据中心带来的显著变化是产生了大量的等价设备和路径,从而消除了单点故障,使得网络架构具备高可靠、高性能以及强大的横向扩展(Scale-out)能力。
在这样的数据中心架构下,BGP路由协议往往会被部署到CLOS网络的所有层级(如图1的TOR,Leaf,Spine等设备),用来为数据中心形成简单、统一的超大规模网络。对于BGP的部署来说,除了满足IPv4、IPv6路由传递的基本能力外, BGP的快速收敛、灵活控制、方便运维等能力也是部署设计的关键点。
BGP部署设计要点
本文的目的在于为IDC的BGP路由部署设计提供一些方法参考,场景聚焦在IDC内部Underlay路由设计。
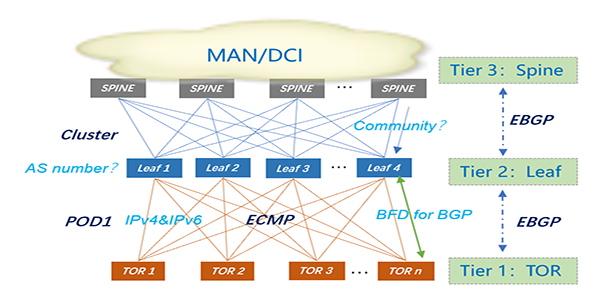
▲ 图2:数据中心BGP部署设计要点
如图2所示,在一个典型的三级CLOS数据中心组网中,BGP设计要点大致可以分为两部分:
一、BGP基础能力规划,包括:
- 为Tier 1-3设备规划AS number;
- 基础BGP参数配置,设备间建立BGP邻居;
- 为CLOS网络生成ECMP等价路由;
- 对不同类型的BGP路由进行路由属性控制;
- 制定路由传递的规则;
- 提供IPv4/IPv6双栈能力;
二、BGP运维能力规划,包括:
- 使用双向转发检测协议(BFD)加快故障收敛;
- 提供不间断的业务能力。
BGP基础能力规划
1、AS number规划
BGP的AS number分为公共AS和私有AS。在IDC内部,虽然AS号不会通告给外部网络,但为了保障安全性,以及延续使用习惯,仍推荐使用私有AS号。
旧的BGP版本(RFC1771定义)留给AS号的长度范围是2个字节,其中用于私有的AS号为1023 个(64512~65534),不足以应付大型IDC成千上万的网元数量。对于这个问题目前有两种解决方案:
- 新的RFC4893《BGP Support for Four-octet AS Number Space》定义了4字节的BGP AS number。这使得AS number和IPv4地址一样多,其中可用于私有AS的范围达到9千万个(4200000000~4294967294)。足以为IDC内部的每台网络设备,甚至每台主机分配一个独立的AS number。
- 考虑到AS number使用的简洁,并确保所有设备都能支持,推荐使用64512~65534的私有AS号,并对AS号码进行全局规划,同一个AS number可以被多个设备重复使用。
以下是一个推荐的AS number分配示例:
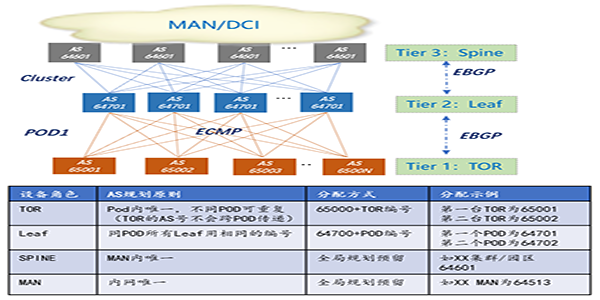
▲ 图3:IDC AS number分配示例
2、BGP基础参数配置
这部分是数据中心实现BGP互通的基础,推荐如下配置:
BGP邻居建立
BGP是基于TCP来建立连接的,因此需要为BGP指定一个IP地址用于建立BGP会话。
在IDC内部推荐使用设备的直连接口地址建立BGP会话。
BGP的Router-id
仅仅是一个标识,设置为交换机的管理口地址或者loopback地址都是不错的方法。
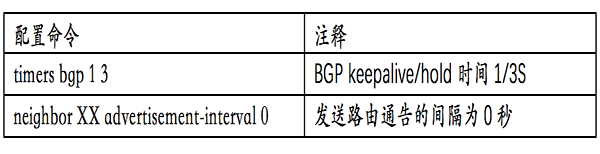
BGP计时器
BGP需要使用keepalive消息来实现会话的保活,确定下一跳的可达性。如前文所述,BGP最早是设计应用于不同自治系统(服务商)之间互联的。不同AS之间路由的稳定性比快速收敛更为重要,为了防止路由震荡,BGP协议默认的计时器非常长,其keepalive/hold timer分别是60S和180S。而在数据中心内部,故障的快速收敛更为重要,推荐采用1S/3S的BGP计时器配置加快收敛。BGP还有另外一个重要的计时器:Advertisement Interval,即发布路由通告的间隔。在这个周期内的BGP事件会被缓存起来,等待计时器到了后再统一发送。BGP默认的通告间隔是30S。在数据中心需要立刻通告变化,因此推荐的配置是0 S。
以锐捷RGOS软件为例,需要在BGP进程下,对计时器进行配置:
其他推荐的配置
bgp log-neighbor-changes :不打开 debug 的情况下记录BGP 的状态变化信息。
3、BGP ECMP
对于CLOS网络而言,等价多路径是构筑网络可靠性、稳定性的基石。
BGP形成等价路由的前提是开启“多径”multipath的特性,以锐捷RGOS为例,需要配置:
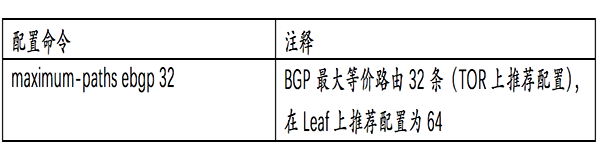
以上只是开启了BGP的多路径能力,接下来需要利用BGP选路的原则,把把多条链路的的下一跳都放入路由表中形成ECMP。13条BGP选路原则中,两条路由等价并执行负载均衡的判断标准是:前8个条件都相同。在数据中心BGP规划中,这前8个条件只需要考虑AS_PATH即可,因为其他条件在IDC都是一致或者无需关心的。
对于AS-PATH属性,在缺省情况下是要求精确比较的,只有AS-PATH的长度和具体AS Number相同时才可能成为等价路径。依据前面的AS Number规划,每台TOR都具备不同的AS号。这样Leaf南向去往同组两台TOR设备的路由无法实现负载分担。上述问题的解决方案是在Leaf设备上使能AS-PATH 宽松比较,以锐捷RGOS为例,需要配置:

如前文的AS规划,在同一Pod中,所有Leaf的AS number相同,因此无论是哪一台Leaf设备发送路由,在TOR上看到的AS-PATH总是一致的。因此Leaf上无需开启宽松比较模式。
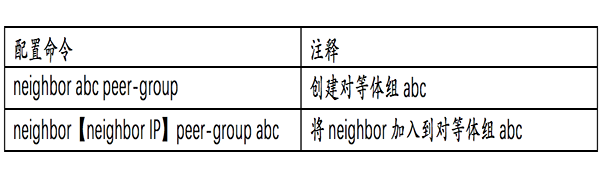
此外,Leaf和TOR之间存在大量的等价邻居,拥有一致的配置策略。实际的部署过程中推荐使用BGP peer-group功能来简化配置。
在锐捷RGOS做如下配置实现该功能:
4、BGP路由属性规划
BGP具备丰富的扩展属性,可以实现强大的路由控制,当前IDC中用的较多的是BGP community属性,可以很大程度简化路由策略。在IDC当中,我们常常会使用到私有的团体属性,用来为前缀加上管理的标记。私有community使用的是AS:number的格式,其中AS是指本地AS号或者对等体AS号,而number是指本地分配好的,用来表示可以应用策略的一组团体。实际使用中我们可以用更简洁的community标记,比如为业务网段打上1:1属性,为内网汇总路由打上2:2属性等,并基于此做路由传递的精细控制。
5、制定路由传递规则
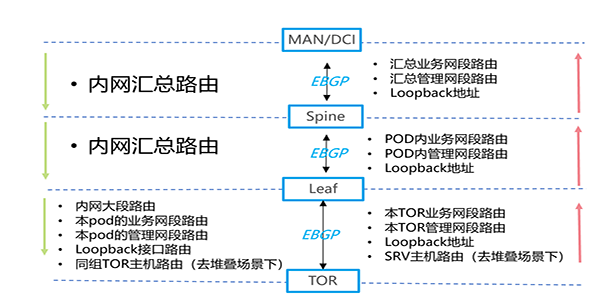
▲ 图4:数据中心BGP路由通告规划
如图4所示,多组TOR+Leaf组成一个POD(最小交付单元,Point of delivery,作为数据中心基本物理设计单元)。Spine负责横向连接多个POD,而MAN/DCI负责提供跨区域的互联。IDC的BGP路由规划建议如下:
- 北向路由传递
TOR至Leaf至Spine至MAN/DCI,逐级通告业务网段+管理网段+Loopback,在去堆叠场景时TOR需要向Spine通告主机路由。
- 南向路由传递
MAN/DCI至Spine至Leaf,传递整个内网的汇总路由,比如10.0.0.0/8;172.16.0.0/12;192.168.0.0/16。而Leaf至TOR,除了通告内网汇总路由外,还需要通告本Pod的业务网段+管理网段+Loopback(当Leaf上行链路故障时,同POD的流量仍可以匹配明细路由,通过Spine转发)。
值得注意的是
目前TOR层级越来越多地使用了去堆叠技术实现服务器双归(推荐参考技术盛宴的另一篇文章《如何实现数据中心网络架构“去”堆叠》)。在去堆叠场景下,Leaf会从ToR交换机上接收到大量的主机路由(取决于Pod内主机数量,可能是数以万计),Leaf在TOR之间传递主机路由,很可能导致TOR交换机路由容量超限,因此需要在TOR的收方向做策略,过滤掉其他TOR发过来的主机路由。
6、BGP双栈规划
近年来国家大力推动IPv6建设,实际上大型IDC私网地址也面临枯竭。因此在IDC内部署IPv4/IPv6双栈,也是迫在眉睫的需求。
BGP本身支持多协议,可以在同一个BGP进程中支持v4/v6双栈。一般的做法是为BGP v4和v6邻居分别建立BGP会话,但这样相当于增加了一倍的配置和维护工作量。实际上,BGP v4的update消息可以通过v6建立的 TCP连接来发送,反之亦然,即单个连接允许多种协议族的消息通告。
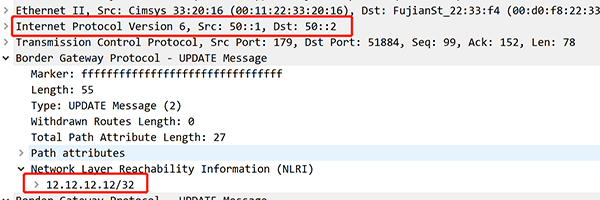
▲ 图5:在IPv6 Session上通告IPv4路由信息
如图5所示,锐捷网络提供了一种优化方案:只建立单会话来承载双栈的路由,这样做的好处除了简化配置、节省IP,还为类似BFD for BGP等协议的部署减少了一半的性能消耗。
BGP运维能力规划
除了要考虑BGP基础能力的规划,数据中心对于BGP网络可运维能力也提出了很高的要求。常见的BGP运维能力的设计包括如下几点:
1、使用BFD技术加速BGP网络收敛
虽然IDC网络是以高度冗余来构建的,但网络的可靠性仍受限于网络设备检测出故障,并重新将流量路由到其他的路径的能力(尤其是在光模块或者光纤出现单通的极端情况下)。当下数据中心,故障收敛时间要求越低越好(云业务要求做到亚秒级)。如前文所述,可以通过修改BGP计时器加速收敛,但这种慢hello机制收敛时间尽快也是秒级,还不足以满足要求。
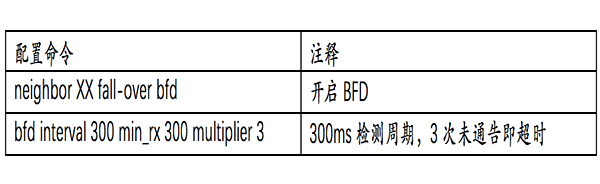
而BFD可以提供毫秒级的检测精度,通过与BGP联动,可以实现BGP路由快速收敛,确保业务连续。在数据中心IDC中推荐开启BFD for BGP的设置,考虑到设备性能,全端口开启时推荐采用300ms*3配置。
以锐捷RGOS软件为例,BFD主要配置如下:
2、不间断业务能力-BGP快速切换
BGP路由收敛需要在路由表中删除失效路由,并增加新的路由,同时在芯片转发表中实现对应的增、删。在存在大量路由的情况下,逐条删除并刷新路由表需要一定的时间,收敛时间可能达到数秒甚至数十秒。锐捷RGOS软件在路由收敛上提供了优化的手段:支持前缀无关收敛。如图6所示,Leaf 1设备到Spine设备所有EBGP邻居都失效时,Leaf 1会向所有TOR通告去往Spine的 AS不可达。TOR接收到此消息,查找预先分配好的对应的ID索引(依据Spine的AS号及Leaf的Router-ID分配),通告转发表进行下一跳切换,从而实现业务的快速收敛,其收敛速度不再受限于路由条目数。(某大型互联网公司实测12K路由,收敛时间0.7秒)
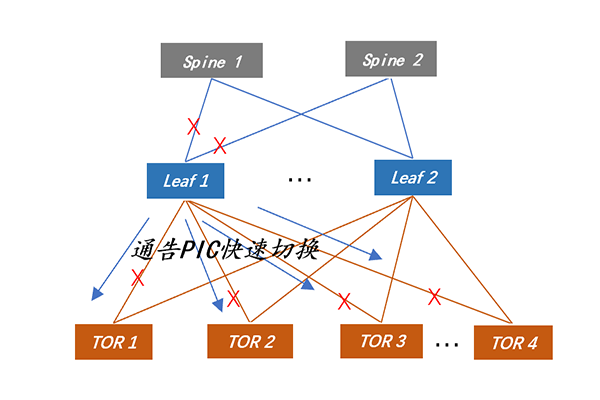
▲ 图6:BGP前缀无关收敛
3、不间断业务能力-BGP NSR
数据中心的Leaf/Spine设备对可靠性要求比较高,大多数配置了双管理板;对于TOR设备,在堆叠组网场景下,也实现了类似双管理板的效果。主备管理板在发生切换时,由于状态信息的不一致很容易引起协议震荡。
NSR(None-Stop-Routing,不间断路由),是为了实现交换机管理板主备切换时,在协议的重新启动过程中路由不间断而设计的。使能NSR功能后,会打开TCP nss(none-stop-service)服务,开始备份相关邻居以及路由信息到从板。在管理板主备切换过程中,NSR 功能使网络拓扑保持稳定,维持邻居状态和转发表,保障关键业务不中断。
4、不间断业务能力-BGP平滑退出和延迟发布
BGP平滑退出:在CLOS数据中心网络中,在对设备进行隔离升级等类似操作时,使用BGP平滑退出功能可以确保业务不断流或者很少断流。
其实现步骤是:
- 首先向邻居设备通告优先级低的路由(local-preference 值为0 或med 值为4294967295),并且会携带知名的gshut community,从而使邻居设备进行路由更新,使其流量预先切换到备份链路或其他等价链路上。
- 接着再延迟一定时间,确保路由学习完成之后,断开与邻居设备间的BGP 连接。
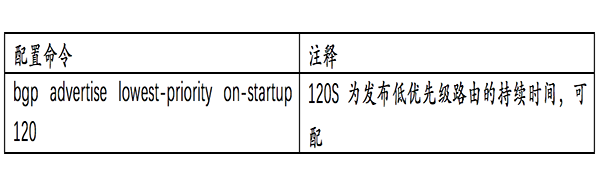
BGP延迟发布:在设备重启时,可能会存在路由表还未下发到本地的硬件表项,却将路由信息通告给邻居,从而提前引流导致流量转发异常的情况。为避免此问题,可以设置BGP在整机重启时把发布的路由调整为低优先级
该能力建议在设备中预配置,以锐捷RGOS为例,需配置:
写在最后
规划、建设和运营好数据中心BGP网络,是一件非常不容易的事情,这需要大量的实践经验积累。所幸的是BGP在IDC的应用已经日趋成熟,大型互联网公司、运营商有非常多实践案例可以参考。锐捷网络也有幸参与其中,为腾讯、阿里巴巴、字节跳动等客户交付了多个大型BGP数据中心网络。
关于BGP性能优化以及更多BGP运维特性,敬请期待技术盛宴后续分享。
相关推荐:
相关标签:


点赞



,RG-S6510-48VS8CQ")




更多技术博文
-

 多速率交换机是什么?一文明白其原理、优势与锐捷方案推荐
多速率交换机是什么?一文明白其原理、优势与锐捷方案推荐本文用通俗语言详解多速率交换机是什么,包括其工作原理、三大核心优势及四大应用场景。文末为您推荐锐捷RG-S6100系列与RG-S5315-E系列交换机的选型方案,助您实现平滑网络升级。
-
#交换机
-
-
 解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。
-
#交换机
-
-
 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
















