超大规模组网
极致高吞吐网络
快速部署上线
AI智能运维
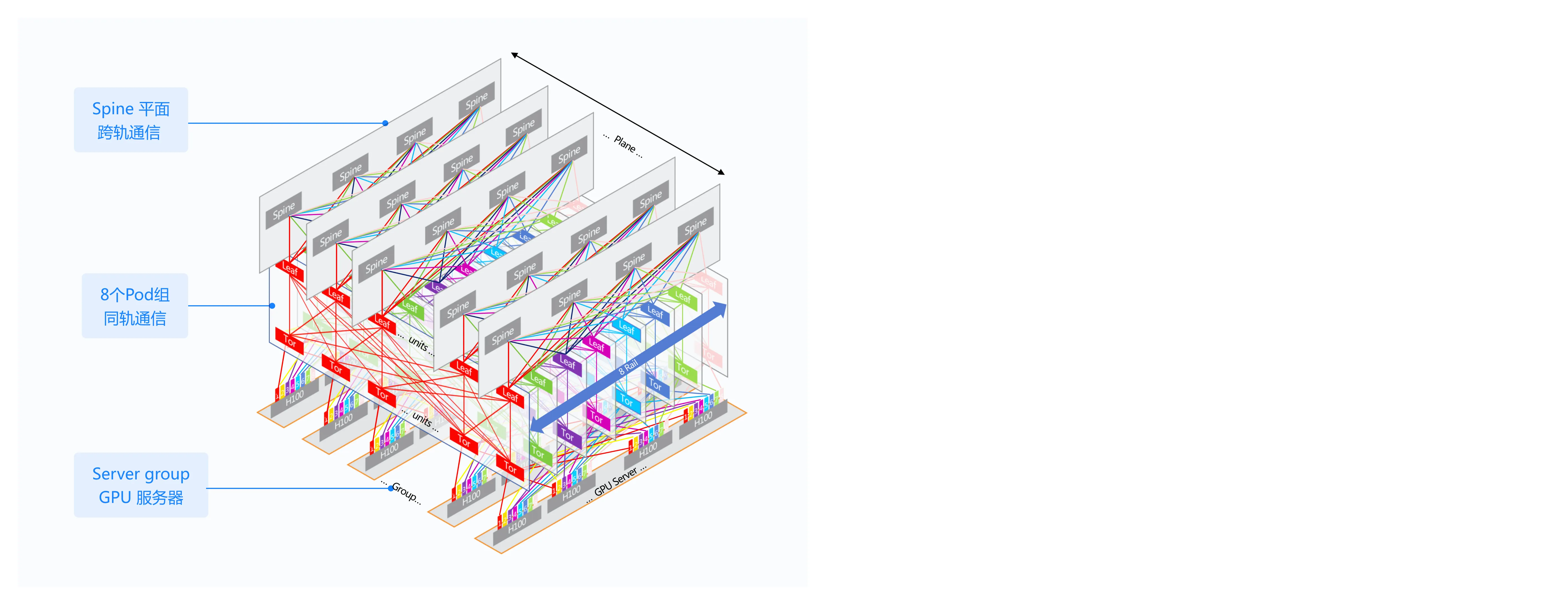
GPU服务器通常配置多张网卡用于参数训练,为了提升GPU训练效率,保障集群通讯的低时延无损通信,锐捷网络AI-Fabric网络解决方案采用多轨组网架构,让同号网卡连接到同一网络Pod组内,使训练业务的流量限定在同一Pod组或同一Tor设备上,从而减少转发跳数,大幅降低网络转发时延;同时为了构建高算力的大规模GPU集群,锐捷网络AI-Fabric网络解决方案采用三级组网,各层级按照1: 1的收敛比的设计,最大可以提供32768个400G端口,实现32K个GPU的集群承载。
AI-Fabric 三级多轨组网架构
三级组网:承载GPU大规模集群,实现服务器间的高速通信;
多级架构:减少转发跳数,降低通信时延,提升业务亲和力;
单芯片25.6Tbps,盒-盒架构
- 交换机端口: 64 x 400GbE
- 二级组网架构:最大 2K GPU
- 端口SerDes : 56Gbps
- 三级组网架构:最大 8K GPU
单芯片25.6Tbps,盒-盒架构
- 交换机端口: 128 x 200GbE
- 二级组网架构 : 最大4K GPU
- 端口SerDes : 56Gbps
- 三级组网架构 : 最大16K GPU
单芯片51.2Tbps,盒-盒架构
- 交换机端口: 128 x 400GbE
- 二级组网架构 : 最大8K GPU
- 端口SerDes : 112Gbps
- 三级组网架构 : 最大32K GPU
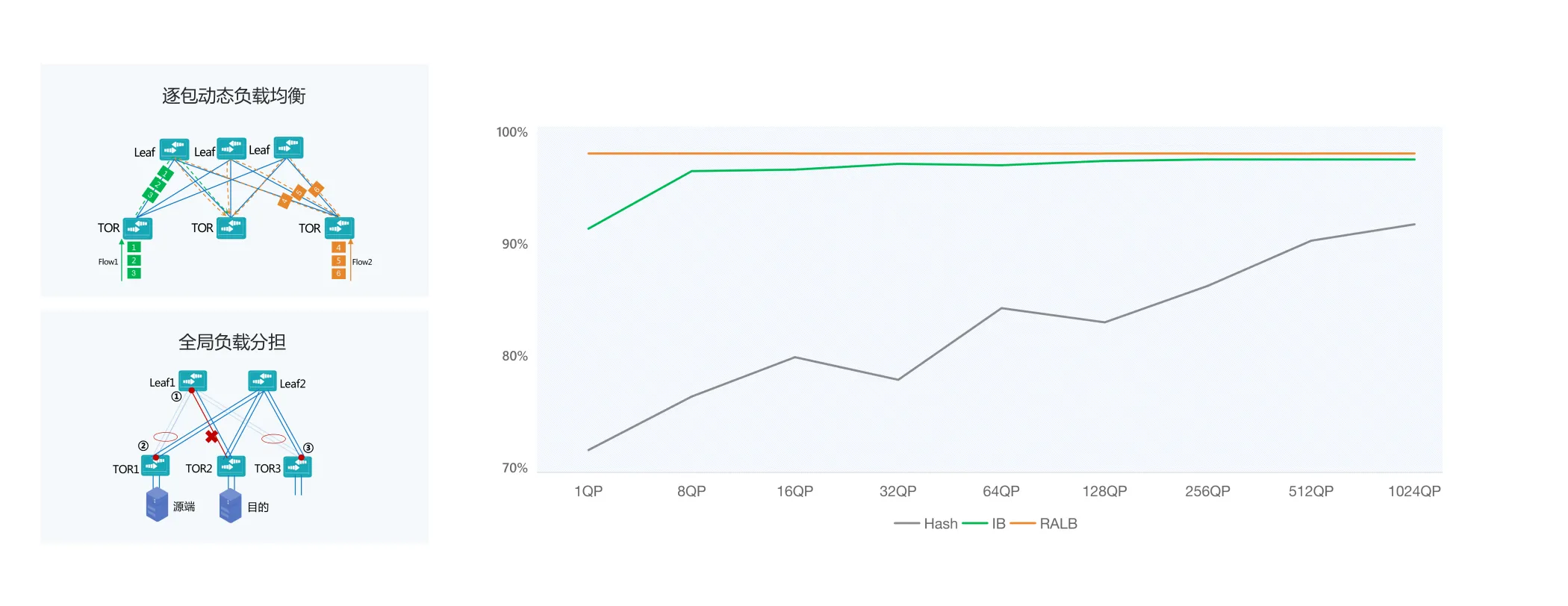
采用400G的RoCE方案,实现低时延、无损网络通信
通过锐捷RALB技术感知链路质量,实现逐包的全局动态负载均衡,让网络带宽利用率达到97.6%
带宽利用率97.6%
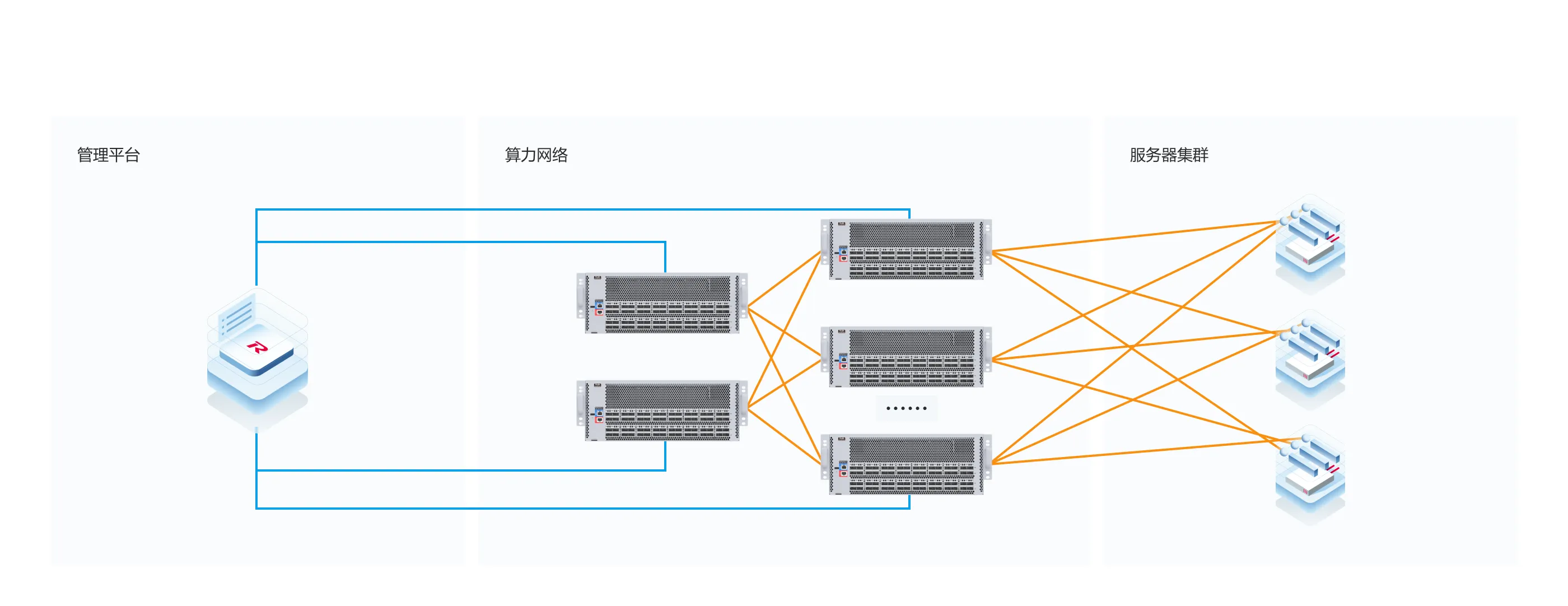
一键即可完成ECN、PFC等RDMA网络下复杂的配置导入,实现快速部署。借助丰富的互联网头部厂商大型AI组网的部署经验,助力网络快速开通
同时兼容市面上主流云平台厂家,无需额外适配工作,实现业务快速上线。
RoCE一键部署
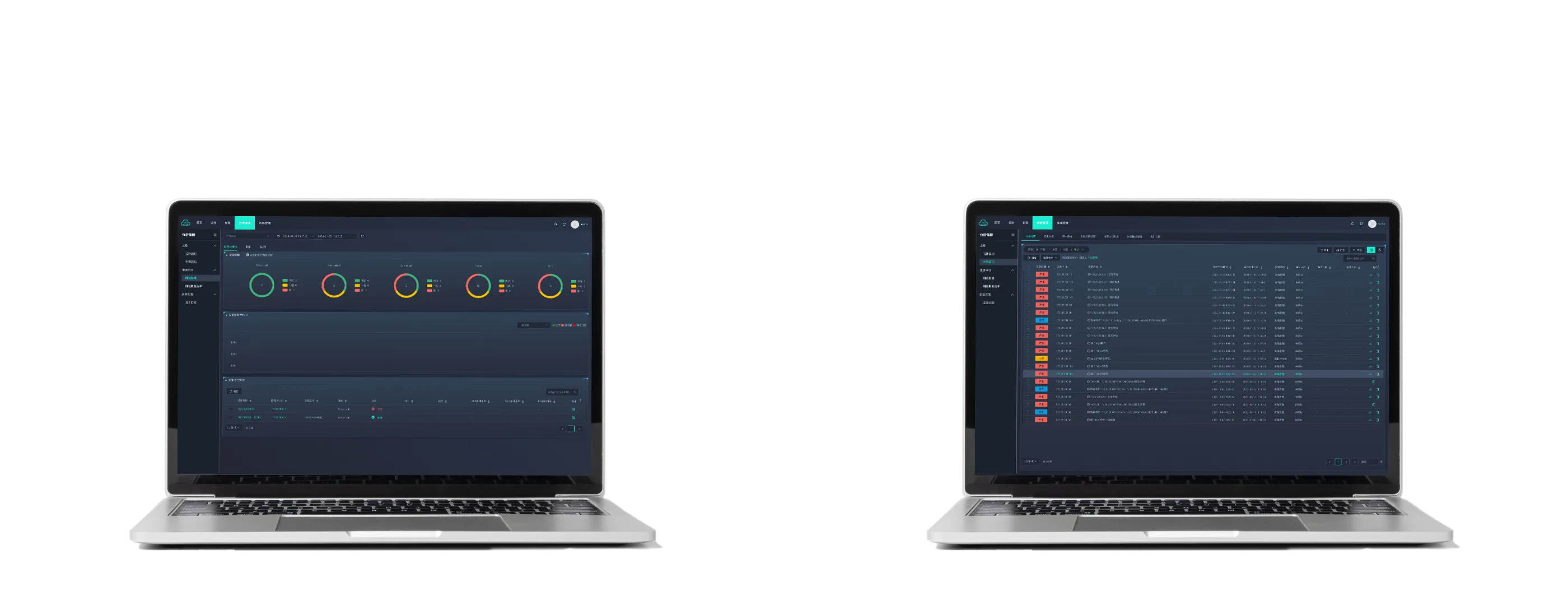
基于大数据及AI算法,对整网数据综合分析。主动发现异常,网络指标精准呈现链路异常。
设备和端口快速隔离,缩小故障范围
网络健康度精准分析
主动发现异常,网络指标精准呈现
业务指标深度遥测
基于大数据及AI算法,对整网数据综合分析